ublo
bogdan's (micro)blog

bogdan » Moving from Stateless LLMs to Situated Intelligence
10:45 pm on Jun 10, 2026 | read the article | tags: medium
We’ve spent the last few years treating LLMs as if their main advantage is that they know almost everything. They can explain quantum mechanics, debug a convoluted CSS grid layout, and rewrite Romanian manele (you have been warned!) lyrics in the voice of Constantin Noica. But there is a fundamental mismatch between how these models work and how we actually make decisions.
The basic LLM interaction is still mostly stateless. Even when products add chat history or file uploads, the model itself does not automatically maintain an inspectable, evolving model of your projects, stakeholders, failed attempts, beliefs, and outcomes. You end up re-explaining the same constraints, re-contextualizing the same stakeholders, and re-hashing the same history. It’s like trying to lead a project while suffering from short-term memory loss.
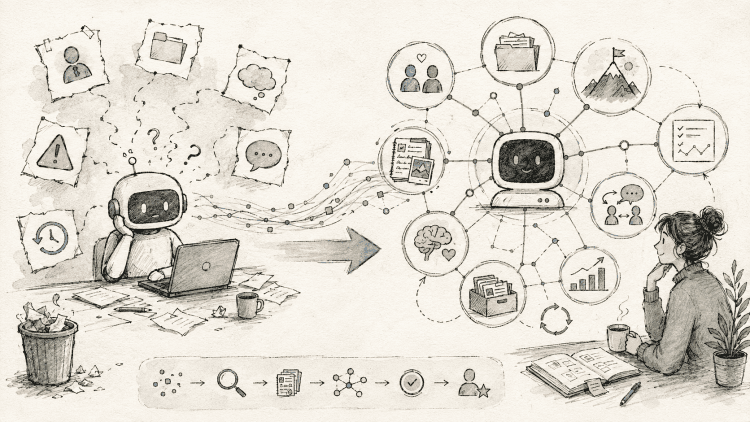
I built SecondContext to bridge that gap. It is a prototype for an LLM assistant that behaves more like a situated expert: a system that accumulates experience alongside you.
Rather than treating every interaction as a blank slate, SecondContext operates as a persistent cognitive layer. It stores structured memories about people, projects, beliefs, and outcomes. If I ask it to help me draft an infrastructure proposal review for Alex, it doesn’t just output generic corporate filler. It has context that Alex is competent but perpetually busy, that he responds better to a narrow, API-focused scope, and that my previous attempts worked only when I presented a specific technical constraint. The assistant doesn’t just draft the message; it suggests the strategy, warns me about the risks, and generates follow-up scenarios based on how these people have responded to me in the past.
The common engineering answer to this problem is RAG: Retrieval-Augmented Generation. RAG is useful, but most systems are optimized for retrieving facts from static documents. SecondContext uses retrieval too, but the object being retrieved is different: not only documents, but accumulated work context: people, outcomes, preferences, failed strategies, uncertainty, and changing beliefs.
There is an obvious risk here: a memory system about people can become creepy or overconfident very quickly. That is why I think the important design principle is not just persistence, but inspectable persistence. SecondContext stores evidence, confidence, timestamps, and uncertainty; it distinguishes observations from interpretations; and it makes memories editable and deletable. A situated assistant should not secretly profile people. It should expose the assumptions it is using.
This architecture also aligns with the academic work around CoALA: Cognitive Architectures for Language Agents. I didn’t set out to build a formal cognitive architecture. I just wanted an assistant that remembered that Alex hates vague emails. But looking at the literature, the direction feels clear: useful agentic behavior requires a modular way to perceive, store, retrieve, act, and update. SecondContext is a practical, narrow-scoped implementation of these principles. It is a move toward building agents that aren’t just smarter, but more situated: able to function as persistent teammates rather than search engines trapped in chat boxes.
I’ve intentionally kept the stack boring: Go, Postgres, and Qdrant. No proprietary, un-debuggable decision layer. The goal is to keep the system inspectable and transparent. If the assistant gives a bad recommendation, I want to see exactly why it retrieved that specific memory, how it scored that strategy, and what evidence led to its current belief.
The current version is already a working MVP, with a baseline that supports memory ingest and search, hybrid retrieval, salience reranking, person/topic summaries, belief tracking, scenario generation, outcome feedback, and a debug view for comparing stateless versus memory-augmented responses.
This is still an experiment. It is narrow, early, and intentionally boring in its implementation. But it is testing a simple hypothesis: for recurring work, intelligence without memory is mostly a party trick. Intelligence with inspectable memory, feedback, and uncertainty can become a real tool.
You can find the architecture, demo, and code here: https://github.com/bdobrica/SecondContext
find me:
in my mind:
- #artist 2
- #arts 4
- #away 3
- #bucharest 1
- #buggy 6
- #business 1
- #clothes 1
- #comics 1
- #contest 3
- #dragosvoicu 1
- #education 1
- #food 2
- #free-ideas 1
- #friends 14
- #hobby 23
- #howto 9
- #ideas 33
- #life lessons 4
- #me 59
- #medium 4
- #mobile fun 4
- #music 51
- #muvis 17
- #muviz 13
- #myth buxter 1
- #nice2know 15
- #night out 1
- #openmind 2
- #outside 3
- #poems 4
- #quotes 1
- #raspberry 4
- #remote 56
- #replied 51
- #sci-tech 7
- #sciencenews 1
- #sexaid 7
- #subway 39
- #th!nk 5
- #theater 1
- #zen! 4