ublo
bogdan's (micro)blog

bogdan » Stop Searching by Coincidence: Portability and the Storage Decoupling Layer
09:47 pm on Jul 6, 2026 | read the article | tags: medium
Most architecture diagrams are much easier to understand after the system has already been built. You look at the boxes, see an API gateway connected to an embedding model, a vector database, a message broker, and a relational database, and the design appears almost inevitable. Of course the query goes there. Of course ingestion goes through a queue. Of course the model is separated from the application.
The problem is that real systems rarely emerge that cleanly. They grow from constraints. One choice creates pressure somewhere else. Solving that pressure introduces another requirement. Eventually, the architecture starts to look deliberate, but the interesting part is not the final diagram. The interesting part is understanding why the boundaries exist in the first place.
The system I have been building powers SearchPixel, but the infrastructure is intentionally broader than a WordPress search plugin. At its core, it is infrastructure for multi-tenant semantic search and retrieval workloads. It needs to accept documents, transform them into representations suitable for retrieval, store those representations, execute low-latency hybrid searches, and remain flexible enough that neither the vector database nor the machine learning model becomes a permanent architectural dependency.
The system uses Kubernetes as its infrastructure backbone, a Go API gateway as its coordination layer, Snowflake Arctic as the primary embedding model, Qdrant as the primary vector database, MySQL for tenant and credential configuration, and NATS for the asynchronous ingestion path.
![]()
Kubernetes Was the First Architectural Boundary
I started with Kubernetes before choosing most of the application components. That may sound backwards, as a common approach is to build the application first and decide how to deploy it later. For this system, infrastructure portability was already one of the product requirements, so deployment could not be treated as an implementation detail. I wanted to preserve two very different operating modes.
At one end, I wanted the ability to run on a public cloud using a managed control plane. At the other end, I wanted to be able to move the same workloads onto cheaper infrastructure and operate the cluster myself when cost became more important than convenience. Those two environments are not identical, and I do not pretend Kubernetes magically erases every difference between providers. Storage, networking, load balancers, GPU availability, and node provisioning remain provider-specific concerns. What Kubernetes gives me is a stable operational boundary above those differences.
My model servers are pods. The API gateway is a deployment. Qdrant is stateful infrastructure with persistent storage. NATS is another network service. Configuration is declarative. Service discovery follows the same conceptual model regardless of whether the nodes underneath happen to come from a large public cloud or from a cluster I manage myself.
That distinction matters because cost curves change as systems grow. A managed service can be an excellent choice when operational simplicity is more valuable than infrastructure cost. The calculation changes when traffic becomes predictable, when workloads are large enough to justify dedicated nodes, or when expensive inference hardware dominates the bill. I did not want a future decision to move infrastructure to require redesigning the application at the same time. Kubernetes therefore became less of a deployment tool and more of an architectural portability layer.
There was another reason for making that choice early. Machine learning infrastructure is unusually heterogeneous. An API service, an embedding model, and a vector database do not scale in the same way. They do not have the same memory profile. They do not start at the same speed. They do not fail for the same reasons. A stateless network service may scale horizontally in seconds. A model server may need a large artifact before it can answer its first request. A vector database may need stable local storage and careful placement. I wanted an infrastructure substrate where those workloads could coexist without pretending they were the same.
This decision also explains my preference for relatively plain Kubernetes manifests, Kustomize, and FluxCD. I am not opposed to Helm in principle. I simply prefer to keep the deployment model visible when I am responsible for operating the system, especially because I pay for this infrastructure out of my own pocket. I want to be able to inspect a StatefulSet and understand what is running, how storage is mounted, how a node starts, and where configuration comes from.
Isolating Storage via the Adapter Pattern
Semantic search systems have a natural tendency to organize themselves around the vector database. It makes sense, because the vector store sits directly on the critical query path. It contains expensive derived data. Its indexing strategy affects latency, recall, memory consumption, and operational cost. Once enough data accumulates, migrating away from it can become painful. That is exactly why I did not want the rest of the system to become structurally dependent on one database.
Today, Qdrant is my primary vector engine. I wrote a separate article about why I chose it, so I will not repeat that evaluation here. The more important architectural decision is that Qdrant is a routing target, not the identity of the platform.
In practice, the storage decoupling layer is not a universal database API. It is the combination of tenant-aware placement, backend-specific adapters, and a gateway that keeps those decisions away from clients. To achieve this, the gateway isolates backend-specific behavior behind small storage adapters. The request path resolves the tenant’s configured backend and dispatches the operation to the corresponding implementation. The goal is not to pretend every vector database has identical semantics. It is to keep backend placement and backend-specific query construction out of the external API and the higher-level request flow. When a request reaches the gateway, the system does not simply assume a collection or index structure. Instead, tenant configuration identifies both the backend type and the target indexing node. The gateway resolves that placement at request time and sends the operation through the corresponding backend adapter.
My current production gateway code still contains both Qdrant and RediSearch paths operating behind this abstraction layer. This design choice is larger than merely preserving backward compatibility with Redis. I do not believe a single vector database will necessarily remain the correct answer for every retrieval workload, because the underlying ecosystem is changing too quickly for that assumption to be comfortable. Databases are constantly adding sparse vectors, new quantization techniques, disk-backed indexes, late interaction support, GPU acceleration, and different approaches to distributed search. A design that is optimal today can become an operational bottleneck surprisingly quickly.
There is also a more fundamental distributed systems reason for application-level database routing. Horizontal scalability is not infinite in the way abstract cloud marketing benchmarks suggest. It is easy to say that a database scales horizontally, but that phrase hides the cost of coordination. As a distributed dataset grows, queries may touch more partitions, replication consumes more bandwidth, rebalancing becomes more expensive, coordination surfaces expand, and tail latency becomes increasingly sensitive to the slowest participant in a distributed operation. At some point, depending on the workload, adding more capacity to a single logical database cluster produces diminishing returns.
For a multi-tenant system, this is especially important because tenants already provide a natural partitioning dimension. There is no inherent reason every independent website must live inside one globally scaled vector database cluster. A collection of tenants can be assigned to one Qdrant deployment, another collection to a second deployment, and a particularly heavy tenant can be completely isolated on its own dedicated database node if its workload justifies it.
Consider a deployment serving thousands of relatively small websites. Most of them may fit comfortably on a shared Qdrant cluster. Then one customer arrives with a catalogue larger than hundreds of existing tenants combined and a sustained query profile that changes the capacity model. I do not want the only response to be scaling the shared cluster for everyone. The routing layer gives me another option: place that tenant elsewhere without changing the client API or forcing unrelated tenants to absorb the operational consequences.
Independent deployments also create a useful failure boundary. Scaling is not the only reason to separate workloads; sometimes the goal is simply to prevent one pathological tenant or one overloaded cluster from becoming everybody’s incident.
Database sharding asks how to distribute data inside a database system, whereas application-level routing asks whether all data needed to be inside the same database system in the first place. For a strongly multi-tenant workload, I want both options. That is why the indexing node and indexing backend belong to tenant configuration rather than being hardcoded into application logic. It means that introducing another vector engine later can remain primarily a local adapter problem rather than becoming a platform-wide migration.
Decoupling storage solved one class of future migration, but it exposed the next assumption in the system. A hybrid search request does not begin at the database. It begins with a machine learning model, and those models evolve even faster than storage engines. The moment I accepted that the vector database could not define the platform, I had to admit that the embedding model could not define it either. That is where the next part begins.
bogdan » Stop Searching by Coincidence: Why I Swapped RediSearch for Qdrant
12:05 am on Jun 25, 2026 | read the article | tags: medium
This is the next step in my series that started with Stop Searching by Coincidence. In my last post, I argued that hybrid search isn’t optional for e-commerce relevance. But making that theory boringly reliable in production? That’s another beast. This article is about that second step: choosing the engine that could carry it all.
My constraints were not your typical, venture-backed «RAG startup» constraints. Though I wish they were! If you’re a VC looking to write a check, don’t be shy. Back to the topic: they were operationally specific, born from firsthand experience managing hundreds of millions of vectors across thousands of collections, all while hitting tight, double-digit millisecond latency targets for thousands of requests per minute. Building this production system on my own, on infrastructure I’m paying for, and having to manage it outside of working hours, changes the math. I don’t have the luxury of wrestling with the unnecessary abstraction layers that complex Helm charts often introduce. I want maximum predictability and zero black boxes, which is why I’m keeping the database tier raw while still leveraging FluxCD for clean GitOps.
When you view the database landscape through that lens, the options narrow quickly. If all I wanted was raw capability, Vespa would have stayed in the final round longer. If all I wanted was a giant distributed vector platform, Milvus would have stayed there too. If all I wanted was managed convenience, Pinecone would be hard to ignore.
But I needed a serious vector database that delivers sparse vectors, native hybrid search primitives, predictable persistence, and a deployment model that feels close to «run the binary, mount the volume, wire the StatefulSet».
That is how I ended up choosing Qdrant. It provides first-class sparse vectors, server-side fusion (RRF/DBSF), robust snapshotting, and an elegant single-process model written in Rust that leaves less operational surface area than its multi-service competitors.
But let’s be perfectly honest: Qdrant isn’t magic, and getting it to fit my architecture required tearing up my original playbook.
The Problem I Was Actually Solving (And the Redis Breaking Point)
A lot of vector database comparisons quietly assume a single large corpus, one product team, and one clean retrieval stack. What I am building with my plugin is closer to a fleet problem: managing thousands of independent e-commerce sites.
I wasn’t starting from zero. The early versions of the architecture relied on a Redis + RediSearch setup. I liked it. It was fast, and it fit naturally with per-site allocation using a custom knapsack strategy across master/replica pairs. In fact, the current codebase still supports RediSearch. I deliberately kept it there because I’m considering offering a self-hosted «appliance» version down the road: a quick Docker Compose or Helm chart for people who want to index internal documents on their own iron.
But for the multi-tenant SaaS scale I wanted, RediSearch hit three massive walls:
- The Ephemeral Anxiety: I’ve seen firsthand what happens when a RediSearch replica crashes with tens of millions of records on the line. Watching an instance take over two hours to rebuild an HNSW index while repeatedly expanding capacity during startup is the kind of behavior that ages a developer prematurely.
- Rudimentary Hybrid Support: While Redis has introduced tools like
FT.HYBRID, its native hybrid capabilities felt rudimentary compared to dedicated engines. After experiment after experiment, I realized that without deep, server-side hybrid reranking, the search results just weren’t matching user intent. - The Licensing Hand Grenade: The recent Redis licensing shifts threw a wrench into the ecosystem. Compounding that, the early state of search support in open-source alternatives like Valkey meant that betting the future of my infrastructure on this path felt like building on shifting sand.
I also took a hard look at Vespa. I met one of the Vespa developers, and talking to them was actually what triggered my obsession with hybrid search. Vespa is a phenomenal engineering achievement with a brilliant phased-ranking model. But its self-managed architecture requires config servers and Apache ZooKeeper.
Between work deadlines and the occasional overtime, my energy for managing infrastructure after hours is limited. I didn’t want to spend my nights babysitting ZooKeeper.
I needed a lean, boring, cloud-native operating model.
The Shortlist and How It Shook Out
I evaluated the candidates against seven core criteria: performance headroom, true on-disk persistence, native sparse/dense hybrid support, Kubernetes simplicity, multi-tenant scalability, low operational cost, and structural alignment with how I already think about data placement.
| Candidate | Persistence Story | Hybrid / Sparse Support | Deployment Shape | Best Fit | My Read |
|---|---|---|---|---|---|
| Qdrant | Snapshots, mmap/on-disk HNSW. Shards ready immediately on target. | First-class sparse vectors; server-side RRF and DBSF. | Single binary/container. Built-in cluster mode. | Teams wanting serious vector search without platform bloat. | Chosen |
| Weaviate | Persistent storage and crash-tolerant writes. | Native BM25 + vector hybrid. | Kubernetes path is heavily Helm-first. | Teams wanting an all-in-one stack comfortable with Helm. | Good tech, wrong operational shape for me. |
| Milvus | Highly durable distributed layers, but broad dependency footprint. | Native BM25 and sparse vectors. | Requires an Operator/Helm; relies on etcd, Pulsar, and MinIO. | Massive enterprise teams with dedicated infra engineers. | Incredibly powerful, far too heavy for a lean project. |
| Vespa | Mature serving engine; self-managed requires ZooKeeper. | Peerless hybrid ranking flexibility. | Operator/Helm-based; substantial footprint. | Search-centric enterprises willing to operate heavy machinery. | Brilliant engineering, but a massive operational commitment. |
| Pinecone | Managed-first. “Pinecone Local” is just an emulator. | Excellent hybrid and sparse support. | SaaS-only; poor fit for self-hosted K8s constraints. | Teams optimizing for zero-ops over control. | Violates my requirement for infrastructure control. |
And Qdrant Won (also the Naming Pivot)
When I first started sketching out this project, I called it ThinkPixel. I liked the sound of it, but when I ran it by my successful plugins-developing friends, they gave me some blunt, necessary feedback: “Make it explicit. Put ‘Search’ in the name.” They were right. The project became SearchPixel, and Qdrant became its engine.
Qdrant won because it nailed the operational sweet spot. Its clustering model is built right into the core process itself. To spin up a cluster, you enable cluster mode, give the first peer a --uri, and let the other peers join with a --bootstrap command. Conceptually, it behaves like a single clustered storage process rather than a massive distributed ecosystem.
Furthermore, independent evaluations (like Reddit Engineering’s public write-up) confirm that while platforms like Milvus excel at decoupling ingestion from query loads at massive scale, Qdrant consistently wins on raw, single-node query latency. For SearchPixel, a simpler architecture with blazing p99 latency was vastly more valuable than a sprawling ecosystem built for someone else’s scale.
The Multitenancy Reality Check
I do not want to oversell it: arriving at this setup came with a heavy dose of initial architectural frustration.
My original plan was simple: create one physical Qdrant collection per WordPress site. It mirrored my Redis mental model perfectly. Then I hit a wall in Qdrant’s production documentation:
Do not create thousands of tiny collections. It is an explicit anti-pattern that destroys performance and spikes metric cardinality.
I was incredibly frustrated. I almost walked away. But instead of abandoning the engine, I looked at how to adapt.
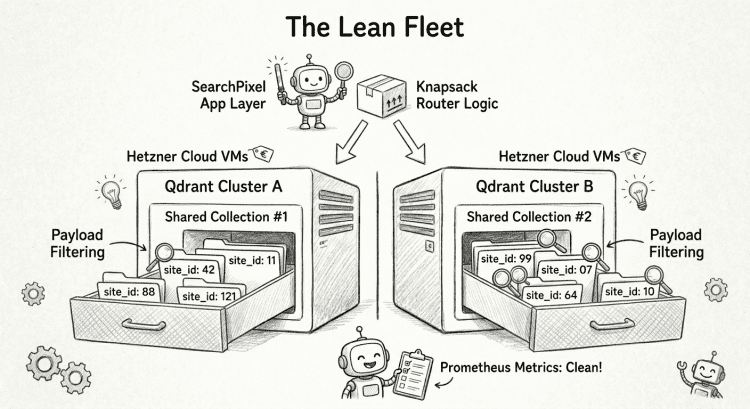
Instead of creating 100,000 separate collections, the correct pattern is to create a modest number of large, shared collections grouped across multiple independent Qdrant clusters. I use a payload index on site_id (marked with is_tenant: True) and force a filter on every single incoming query.
By combining Qdrant’s payload filtering with my existing knapsack allocation logic at the application layer, I got the best of both worlds:
- Bounded Blast Radius: A noisy neighbor site can only impact the specific cluster slice it sits on, not the whole fleet.
- Scale Without Bloat: I avoided turning thousands of sites into thousands of physical collections, keeping Prometheus metrics clean.
- Code Reuse: I got to preserve the scheduling logic I had already spent weeks writing for the original Redis architecture.
How SearchPixel Uses Qdrant in Production
In my production stack, I handle hybrid search entirely on the server side using Qdrant’s Reciprocal Rank Fusion (RRF).
Below is a minimal, production-aligned Python example that runs a true hybrid search against Qdrant: it fuses a sparse (BM25-style) and dense (semantic) query using server-side Reciprocal Rank Fusion, while isolating results by site_id inside a shared multi-tenant collection:
from qdrant_client import QdrantClient, models
def hybrid_search(indexing_node: str, collection_name: str, dense_vector: list[float], sparse_vector: dict[int, float], site_id: str, limit: int = 20):
# Initialize the Qdrant client (connects to the node handling this site)
client = QdrantClient(url=indexing_node)
# Perform a hybrid query with dense + sparse prefetch and server-side RRF fusion
response = client.query_points(
collection_name=collection_name,
# Use `prefetch` to define multiple vector searches that will be fused
prefetch=[
models.Prefetch(
query=dense_vector,
using="dense", # Use the dense vector field
limit=limit,
query_filter=models.Filter(
must=[models.FieldCondition(
key="site_id",
match=models.MatchValue(value=site_id) # Enforce multi-tenant isolation
)]
)
),
models.Prefetch(
query=models.SparseVector(
indices=list(sparse_vector.keys()), # Sparse token IDs (e.g. BM25 terms)
values=list(sparse_vector.values()) # Corresponding weights
),
using="sparse", # Use the sparse vector field
limit=limit,
query_filter=models.Filter(
must=[models.FieldCondition(
key="site_id",
match=models.MatchValue(value=site_id)
)]
)
)
],
# Apply Reciprocal Rank Fusion (RRF) to merge dense + sparse results
query=models.RrfQuery(rrf=models.Rrf(k=60)),
# Final result limit after fusion
limit=limit,
# Fetch only the fields we care about in the result
with_payload=models.WithPayloadSelector(
include=models.PayloadIncludeSelector(fields=["post_id", "text"])
),
)
# Extract simplified result objects
return [
{
"id": point.payload.get("post_id"),
"text": point.payload.get("text"),
"score": point.score
}
for point in response
if point.payload is not None
]
(Note: If you are doing rapid client-side experimentation or complex A/B testing with custom business weights, you can calculate fusion manually in your application code. But for predictable, low-latency production execution, offloading RRF entirely to the database layer is an absolute game-changer.)
The Vanilla Kubernetes Blueprint
To keep operations lean, I bypass Helm charts and operators entirely. Because Qdrant doesn’t require an external cluster state manager, you can coordinate a resilient, self-bootstrapping 3-node cluster natively inside a vanilla Kubernetes StatefulSet.
Here is the exact configuration shape I use to ensure peers bootstrap automatically using the stateful pod network identity:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: qdrant
spec:
replicas: 1 # Single-node for now; can be scaled out later with cluster mode
serviceName: qdrant # Required for stable DNS identity in StatefulSets
selector:
matchLabels:
app.kubernetes.io/name: qdrant
template:
metadata:
labels:
app.kubernetes.io/name: qdrant
spec:
initContainers:
# Ensure volumes have correct ownership before main container starts
- name: ensure-dir-ownership
image: docker.io/qdrant/qdrant:v1.13.4
command: ["chown", "-R", "1000:2000", "/qdrant/storage", "/qdrant/snapshots", "/qdrant/snapshot-restoration"]
volumeMounts:
- name: qdrant-storage
mountPath: /qdrant/storage
- name: qdrant-snapshots
mountPath: /qdrant/snapshots
- name: qdrant-snapshot-restoration
mountPath: /qdrant/snapshot-restoration
containers:
- name: qdrant
image: docker.io/qdrant/qdrant:v1.13.4
command: ["/bin/bash", "-c"]
args: ["./config/initialize.sh"] # Custom script for first-time init or snapshot restoration
env:
- name: QDRANT_INIT_FILE_PATH
value: /qdrant/init/.qdrant-initialized # Used by your script to detect first-time boot
ports:
- name: http
containerPort: 6333
- name: grpc
containerPort: 6334
readinessProbe:
httpGet:
path: /readyz
port: 6333 # Qdrant’s built-in readiness endpoint
securityContext:
runAsUser: 1000
runAsGroup: 2000
runAsNonRoot: true
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true # Enforces tight security profile
volumeMounts:
- name: qdrant-storage
mountPath: /qdrant/storage # Persistent vector index data
- name: qdrant-snapshots
mountPath: /qdrant/snapshots # Snapshot output directory
- name: qdrant-snapshot-restoration
mountPath: /qdrant/snapshot-restoration # Where snapshots get restored from
- name: qdrant-config
mountPath: /qdrant/config/initialize.sh
subPath: initialize.sh # Your bootstrap script
- name: qdrant-config
mountPath: /qdrant/config/production.yaml
subPath: production.yaml # Optional override config
- name: qdrant-init
mountPath: /qdrant/init # Temp marker dir for init checks
volumes:
- name: qdrant-config
configMap:
name: qdrant-config # Provides both the init script and config file
- name: qdrant-init
emptyDir: {} # Used for writing a boot-complete marker file
volumeClaimTemplates:
- metadata:
name: qdrant-storage
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 200Gi
- metadata:
name: qdrant-snapshots
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 200Gi
- metadata:
name: qdrant-snapshot-restoration
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 200Gi
Cluster mode in Qdrant doesn’t require an external consensus service. Instead, I use a tiny initialize.sh script that uses StatefulSet DNS and a consistent peer URI strategy. Pod 0 becomes the initial node, and all others bootstrap from it using –bootstrap.
#!/bin/sh
# Extract the pod index from the StatefulSet hostname
# e.g. qdrant-0 → 0, qdrant-2 → 2
SET_INDEX=$${HOSTNAME##*-}
# For the first pod (index 0), start the cluster and
# become the initial peer
# https://github.com/qdrant/qdrant/blob/master/tools/entrypoint.sh
if [ "$SET_INDEX" = "0" ]; then
exec ./entrypoint.sh --uri 'http://qdrant-0.qdrant:6335'
else
# For other pods, join the cluster by bootstrapping from pod 0
exec ./entrypoint.sh \
--bootstrap 'http://qdrant-0.qdrant:6335' \
--uri "http://qdrant-$SET_INDEX.qdrant:6335"
fi
Moving Forward Natively
If you are currently evaluating vector search engines for a multi-tenant or multi-site workload, save yourself the abstract benchmark review sessions and follow a boring, systematic migration path:
- Build a workload-accurate benchmark: Do not test using random Wikipedia datasets. Use your production product catalog, your exact sparse tokenizer, your real filters, and your real multi-tenant query distributions.
- Pre-index your payloads: Map out fields like
site_id,category, andbrandinto payload indexes before you push data to avoid paying an unindexed disk-access tax later. - Optimize for the bulk load: When performing backfills, temporarily adjust your configuration to drop
indexing_thresholdorm: 0to bypass HNSW graph construction overhead during initial hydration. Re-enable it only when your initial data is warm. - Automate your disaster recovery drills: Rebuild tolerance sounds great in architectural planning sessions, but it’s an entirely different story when an outage hits on a Friday evening. Leverage external, S3-compatible snapshotting from day one.
In the next post in this series, I’ll show you a bird’s-eye view of the overall infrastructure architecture. I’ll break down the main architectural components, map out what lives where, and look at how I’m running this cluster on bare-metal virtual servers inside Hetzner. Spoiler alert: because I appreciate highly performant, remarkably affordable, European-based cloud providers when I’m bootstrapping on my own dime.
If you want to track how to take hybrid search out of the research lab and make it stay completely boring in production, hit the follow button and stay tuned. For now, Qdrant does exactly what I ask of it: stay fast, stay boring, and stay out of the way.
bogdan » Moving from Stateless LLMs to Situated Intelligence
10:45 pm on Jun 10, 2026 | read the article | tags: medium
We’ve spent the last few years treating LLMs as if their main advantage is that they know almost everything. They can explain quantum mechanics, debug a convoluted CSS grid layout, and rewrite Romanian manele (you have been warned!) lyrics in the voice of Constantin Noica. But there is a fundamental mismatch between how these models work and how we actually make decisions.
The basic LLM interaction is still mostly stateless. Even when products add chat history or file uploads, the model itself does not automatically maintain an inspectable, evolving model of your projects, stakeholders, failed attempts, beliefs, and outcomes. You end up re-explaining the same constraints, re-contextualizing the same stakeholders, and re-hashing the same history. It’s like trying to lead a project while suffering from short-term memory loss.
I built SecondContext to bridge that gap. It is a prototype for an LLM assistant that behaves more like a situated expert: a system that accumulates experience alongside you.
Rather than treating every interaction as a blank slate, SecondContext operates as a persistent cognitive layer. It stores structured memories about people, projects, beliefs, and outcomes. If I ask it to help me draft an infrastructure proposal review for Alex, it doesn’t just output generic corporate filler. It has context that Alex is competent but perpetually busy, that he responds better to a narrow, API-focused scope, and that my previous attempts worked only when I presented a specific technical constraint. The assistant doesn’t just draft the message; it suggests the strategy, warns me about the risks, and generates follow-up scenarios based on how these people have responded to me in the past.
The common engineering answer to this problem is RAG: Retrieval-Augmented Generation. RAG is useful, but most systems are optimized for retrieving facts from static documents. SecondContext uses retrieval too, but the object being retrieved is different: not only documents, but accumulated work context: people, outcomes, preferences, failed strategies, uncertainty, and changing beliefs.
There is an obvious risk here: a memory system about people can become creepy or overconfident very quickly. That is why I think the important design principle is not just persistence, but inspectable persistence. SecondContext stores evidence, confidence, timestamps, and uncertainty; it distinguishes observations from interpretations; and it makes memories editable and deletable. A situated assistant should not secretly profile people. It should expose the assumptions it is using.
This architecture also aligns with the academic work around CoALA: Cognitive Architectures for Language Agents. I didn’t set out to build a formal cognitive architecture. I just wanted an assistant that remembered that Alex hates vague emails. But looking at the literature, the direction feels clear: useful agentic behavior requires a modular way to perceive, store, retrieve, act, and update. SecondContext is a practical, narrow-scoped implementation of these principles. It is a move toward building agents that aren’t just smarter, but more situated: able to function as persistent teammates rather than search engines trapped in chat boxes.
I’ve intentionally kept the stack boring: Go, Postgres, and Qdrant. No proprietary, un-debuggable decision layer. The goal is to keep the system inspectable and transparent. If the assistant gives a bad recommendation, I want to see exactly why it retrieved that specific memory, how it scored that strategy, and what evidence led to its current belief.
The current version is already a working MVP, with a baseline that supports memory ingest and search, hybrid retrieval, salience reranking, person/topic summaries, belief tracking, scenario generation, outcome feedback, and a debug view for comparing stateless versus memory-augmented responses.
This is still an experiment. It is narrow, early, and intentionally boring in its implementation. But it is testing a simple hypothesis: for recurring work, intelligence without memory is mostly a party trick. Intelligence with inspectable memory, feedback, and uncertainty can become a real tool.
You can find the architecture, demo, and code here: https://github.com/bdobrica/SecondContext
bogdan » Stop Searching by Coincidence: The Case for Hybrid WordPress Search
05:10 pm on May 17, 2026 | read the article | tags: medium
I like WordPress. I’ve been using it long enough to know where it shines and where it very clearly doesn’t.
Search is one of those areas everyone quietly accepts as “good enough”, until the moment it actually matters. And when it does, you start noticing that WordPress search is not really search in the way users expect it to be. It’s closer to a polite filter. A LIKE query with a UI.
This article is the first in a series where I’ll document how I ended up building SearchPixel, a WordPress plugin backed by a separate search infrastructure that tries to move from string matching to meaning matching.
Before getting into embeddings, hybrid ranking, or architecture, I want to start with the uncomfortable part: why this problem exists at all.
Because if we don’t agree there’s a real problem here, everything else just looks like unnecessary complexity.
What WordPress search actually does
At its core, WordPress search is fairly simple. It takes the query string, splits it into words (loosely), generates an SQL query, then runs a set of LIKE '%term%' conditions over post title, content and excerpt to return whatever matches.
LIKE answers this question:
does this exact sequence of characters appear somewhere in this text?
Users, however, are usually asking something closer to:
which page on this site talks about the thing I’m thinking of?
Those two questions overlap sometimes. Often by accident.
Humans search by meaning. LIKE searches by coincidence.
Users rarely type what you wrote. They type half-remembered ideas, synonyms, typos, vague descriptions, problems, not solutions.
Say you have a post titled:
“How to speed up WordPress with caching and CDN”
Users will search for something like: “site is slow”, “pages load slowly on mobile”, “optimize wordpress performance”, “cloudflare setup”, “cache plugin” or anything else vaguely related. Keyword search might do fine on “optimize wordpress performance”. It might get lucky with “cache plugin”. It will almost certainly miss “site is slow”. Not because the content isn’t relevant, but because relevance here is inferred from string overlap, not from meaning. And overlap is a fragile proxy.
Most improvements follow the same path. Start with better tokenization, weight titles higher, include tags and categories and do fuzzy matching from stemming and synonym lists. At some point, most people end up using an external search engine like Elasticsearch.
All of these help. A lot, actually. But they still rely on the same assumption:
relevance can be inferred from shared tokens
That assumption breaks in very predictable ways, mostly because human beings don’t coordinate their vocabulary with your content.
They will search for “cost” when your button says “price,” or “delivery” when your text says “shipping.” You can patch this by maintaining custom synonym dictionaries. It works, right up until it doesn’t, and you realize you’ve just built a brand-new maintenance problem.
Then, add human error to the mix. Combine fast typing with meme-generating mobile autocorrect, and your logs fill up with “aple,” “wordpres,” and “coudflare.” Keyword search doesn’t know what to do with a typo, so it just returns a blank page.
But the biggest breaking point is intent. If a user searches for “how to migrate” and your top article is titled “Moving between hosting providers”, a LIKE query treats them as entirely unrelated. They share no tokens.
By treating string overlap as a proxy for relevance, you aren’t actually matching intent—you’re just hoping for a linguistic coincidence. This will get worse really fast if you borrow idioms and expressions from other languages in your writing, turning “English” content into something only mostly English.
What hybrid search changes
To fix this, we have to change the underlying math of how search works. We start with semantic search to change the representation. Instead of comparing words, it compares embeddings: vector representations of text that (roughly) encode meaning. Queries and documents that talk about similar things end up closer together in this space. So “site is slow” can retrieve content about caching and CDNs, even if those exact words never appear. It’s not magic. It’s just a different coordinate system.
Keyword search asks: do these words overlap?
Semantic search asks: are these ideas related?
Both questions matter.
But semantic search has its own failure modes. It can be: too fuzzy, too tolerant and most of all surprisingly wrong in very confident ways. Exact matches still matter when you’re looking for error codes, version numbers, product names, quotes or any specific identifiers. Semantic search can rank “kind of related” above “exactly what I asked for”. Which is frustrating.
So this isn’t a “keyword vs semantic” story. It’s a both story. Hence the hybrid.
Why WordPress makes this harder than it sounds
There’s also an architectural reality check. WordPress is PHP, request–response, optimized for publishing and rendering pages. It’s not designed to run transformer models, compute embeddings, maintain vector indexes, perform semantic search, nor keep latency predictable under load. Sure, you can force it, but I wouldn’t recommend it.
The shape that makes sense, in practice, looks like this. You get a WordPress plugin for integration, UI, and content selection, paired with an external service for embeddings, indexing, and retrieval, with a clean API boundary between them.
That’s the direction SearchPixel took.
What SearchPixel is (today)
SearchPixel is a WordPress plugin plus a backend service that indexes selected WordPress content (you choose what goes in), then retrieves a capped number of top results to keep things fast by using a hybrid approach under the hood. All by trying to stay boring in production.
Right now it’s free while I iterate. If operating costs ever become significant, there will probably be a small cost attached because as far as I know, GPUs don’t run on enthusiasm alone.
What’s next
In the next article, I’ll move from “this is broken” to “this is how I designed around it”:
- architecture choices
- what runs where
- indexing trade-offs
- what I limited on purpose
- where latency actually comes from
For now, the short version is this:
WordPress search checks whether your content contains the words.
Semantic search checks whether your content contains the meaning.
Users usually come for meaning. So that’s where I started.
This is part one of an ongoing series building SearchPixel. If you want to catch the next post on architecture choices and indexing trade-offs, hit the Follow button so you don’t miss it.
find me:
in my mind:
- #artist 2
- #arts 4
- #away 3
- #bucharest 1
- #buggy 6
- #business 1
- #clothes 1
- #comics 1
- #contest 3
- #dragosvoicu 1
- #education 1
- #food 2
- #free-ideas 1
- #friends 14
- #hobby 23
- #howto 9
- #ideas 33
- #life lessons 4
- #me 59
- #medium 4
- #mobile fun 4
- #music 51
- #muvis 17
- #muviz 13
- #myth buxter 1
- #nice2know 15
- #night out 1
- #openmind 2
- #outside 3
- #poems 4
- #quotes 1
- #raspberry 4
- #remote 56
- #replied 51
- #sci-tech 7
- #sciencenews 1
- #sexaid 7
- #subway 39
- #th!nk 5
- #theater 1
- #zen! 4