ublo
bogdan's (micro)blog

bogdan » Stop Searching by Coincidence: Why I Swapped RediSearch for Qdrant
12:05 am on Jun 25, 2026 | read the article | tags: medium
This is the next step in my series that started with Stop Searching by Coincidence. In my last post, I argued that hybrid search isn’t optional for e-commerce relevance. But making that theory boringly reliable in production? That’s another beast. This article is about that second step: choosing the engine that could carry it all.
My constraints were not your typical, venture-backed «RAG startup» constraints. Though I wish they were! If you’re a VC looking to write a check, don’t be shy. Back to the topic: they were operationally specific, born from firsthand experience managing hundreds of millions of vectors across thousands of collections, all while hitting tight, double-digit millisecond latency targets for thousands of requests per minute. Building this production system on my own, on infrastructure I’m paying for, and having to manage it outside of working hours, changes the math. I don’t have the luxury of wrestling with the unnecessary abstraction layers that complex Helm charts often introduce. I want maximum predictability and zero black boxes, which is why I’m keeping the database tier raw while still leveraging FluxCD for clean GitOps.
When you view the database landscape through that lens, the options narrow quickly. If all I wanted was raw capability, Vespa would have stayed in the final round longer. If all I wanted was a giant distributed vector platform, Milvus would have stayed there too. If all I wanted was managed convenience, Pinecone would be hard to ignore.
But I needed a serious vector database that delivers sparse vectors, native hybrid search primitives, predictable persistence, and a deployment model that feels close to «run the binary, mount the volume, wire the StatefulSet».
That is how I ended up choosing Qdrant. It provides first-class sparse vectors, server-side fusion (RRF/DBSF), robust snapshotting, and an elegant single-process model written in Rust that leaves less operational surface area than its multi-service competitors.
But let’s be perfectly honest: Qdrant isn’t magic, and getting it to fit my architecture required tearing up my original playbook.
The Problem I Was Actually Solving (And the Redis Breaking Point)
A lot of vector database comparisons quietly assume a single large corpus, one product team, and one clean retrieval stack. What I am building with my plugin is closer to a fleet problem: managing thousands of independent e-commerce sites.
I wasn’t starting from zero. The early versions of the architecture relied on a Redis + RediSearch setup. I liked it. It was fast, and it fit naturally with per-site allocation using a custom knapsack strategy across master/replica pairs. In fact, the current codebase still supports RediSearch. I deliberately kept it there because I’m considering offering a self-hosted «appliance» version down the road: a quick Docker Compose or Helm chart for people who want to index internal documents on their own iron.
But for the multi-tenant SaaS scale I wanted, RediSearch hit three massive walls:
- The Ephemeral Anxiety: I’ve seen firsthand what happens when a RediSearch replica crashes with tens of millions of records on the line. Watching an instance take over two hours to rebuild an HNSW index while repeatedly expanding capacity during startup is the kind of behavior that ages a developer prematurely.
- Rudimentary Hybrid Support: While Redis has introduced tools like
FT.HYBRID, its native hybrid capabilities felt rudimentary compared to dedicated engines. After experiment after experiment, I realized that without deep, server-side hybrid reranking, the search results just weren’t matching user intent. - The Licensing Hand Grenade: The recent Redis licensing shifts threw a wrench into the ecosystem. Compounding that, the early state of search support in open-source alternatives like Valkey meant that betting the future of my infrastructure on this path felt like building on shifting sand.
I also took a hard look at Vespa. I met one of the Vespa developers, and talking to them was actually what triggered my obsession with hybrid search. Vespa is a phenomenal engineering achievement with a brilliant phased-ranking model. But its self-managed architecture requires config servers and Apache ZooKeeper.
Between work deadlines and the occasional overtime, my energy for managing infrastructure after hours is limited. I didn’t want to spend my nights babysitting ZooKeeper.
I needed a lean, boring, cloud-native operating model.
The Shortlist and How It Shook Out
I evaluated the candidates against seven core criteria: performance headroom, true on-disk persistence, native sparse/dense hybrid support, Kubernetes simplicity, multi-tenant scalability, low operational cost, and structural alignment with how I already think about data placement.
| Candidate | Persistence Story | Hybrid / Sparse Support | Deployment Shape | Best Fit | My Read |
|---|---|---|---|---|---|
| Qdrant | Snapshots, mmap/on-disk HNSW. Shards ready immediately on target. | First-class sparse vectors; server-side RRF and DBSF. | Single binary/container. Built-in cluster mode. | Teams wanting serious vector search without platform bloat. | Chosen |
| Weaviate | Persistent storage and crash-tolerant writes. | Native BM25 + vector hybrid. | Kubernetes path is heavily Helm-first. | Teams wanting an all-in-one stack comfortable with Helm. | Good tech, wrong operational shape for me. |
| Milvus | Highly durable distributed layers, but broad dependency footprint. | Native BM25 and sparse vectors. | Requires an Operator/Helm; relies on etcd, Pulsar, and MinIO. | Massive enterprise teams with dedicated infra engineers. | Incredibly powerful, far too heavy for a lean project. |
| Vespa | Mature serving engine; self-managed requires ZooKeeper. | Peerless hybrid ranking flexibility. | Operator/Helm-based; substantial footprint. | Search-centric enterprises willing to operate heavy machinery. | Brilliant engineering, but a massive operational commitment. |
| Pinecone | Managed-first. “Pinecone Local” is just an emulator. | Excellent hybrid and sparse support. | SaaS-only; poor fit for self-hosted K8s constraints. | Teams optimizing for zero-ops over control. | Violates my requirement for infrastructure control. |
And Qdrant Won (also the Naming Pivot)
When I first started sketching out this project, I called it ThinkPixel. I liked the sound of it, but when I ran it by my successful plugins-developing friends, they gave me some blunt, necessary feedback: “Make it explicit. Put ‘Search’ in the name.” They were right. The project became SearchPixel, and Qdrant became its engine.
Qdrant won because it nailed the operational sweet spot. Its clustering model is built right into the core process itself. To spin up a cluster, you enable cluster mode, give the first peer a --uri, and let the other peers join with a --bootstrap command. Conceptually, it behaves like a single clustered storage process rather than a massive distributed ecosystem.
Furthermore, independent evaluations (like Reddit Engineering’s public write-up) confirm that while platforms like Milvus excel at decoupling ingestion from query loads at massive scale, Qdrant consistently wins on raw, single-node query latency. For SearchPixel, a simpler architecture with blazing p99 latency was vastly more valuable than a sprawling ecosystem built for someone else’s scale.
The Multitenancy Reality Check
I do not want to oversell it: arriving at this setup came with a heavy dose of initial architectural frustration.
My original plan was simple: create one physical Qdrant collection per WordPress site. It mirrored my Redis mental model perfectly. Then I hit a wall in Qdrant’s production documentation:
Do not create thousands of tiny collections. It is an explicit anti-pattern that destroys performance and spikes metric cardinality.
I was incredibly frustrated. I almost walked away. But instead of abandoning the engine, I looked at how to adapt.
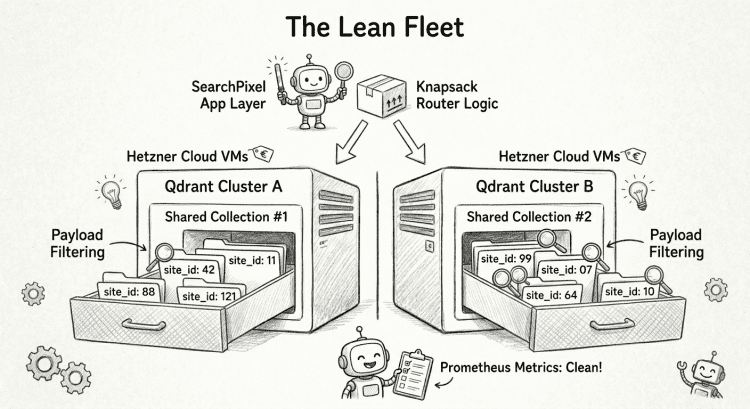
Instead of creating 100,000 separate collections, the correct pattern is to create a modest number of large, shared collections grouped across multiple independent Qdrant clusters. I use a payload index on site_id (marked with is_tenant: True) and force a filter on every single incoming query.
By combining Qdrant’s payload filtering with my existing knapsack allocation logic at the application layer, I got the best of both worlds:
- Bounded Blast Radius: A noisy neighbor site can only impact the specific cluster slice it sits on, not the whole fleet.
- Scale Without Bloat: I avoided turning thousands of sites into thousands of physical collections, keeping Prometheus metrics clean.
- Code Reuse: I got to preserve the scheduling logic I had already spent weeks writing for the original Redis architecture.
How SearchPixel Uses Qdrant in Production
In my production stack, I handle hybrid search entirely on the server side using Qdrant’s Reciprocal Rank Fusion (RRF).
Below is a minimal, production-aligned Python example that runs a true hybrid search against Qdrant: it fuses a sparse (BM25-style) and dense (semantic) query using server-side Reciprocal Rank Fusion, while isolating results by site_id inside a shared multi-tenant collection:
from qdrant_client import QdrantClient, models
def hybrid_search(indexing_node: str, collection_name: str, dense_vector: list[float], sparse_vector: dict[int, float], site_id: str, limit: int = 20):
# Initialize the Qdrant client (connects to the node handling this site)
client = QdrantClient(url=indexing_node)
# Perform a hybrid query with dense + sparse prefetch and server-side RRF fusion
response = client.query_points(
collection_name=collection_name,
# Use `prefetch` to define multiple vector searches that will be fused
prefetch=[
models.Prefetch(
query=dense_vector,
using="dense", # Use the dense vector field
limit=limit,
query_filter=models.Filter(
must=[models.FieldCondition(
key="site_id",
match=models.MatchValue(value=site_id) # Enforce multi-tenant isolation
)]
)
),
models.Prefetch(
query=models.SparseVector(
indices=list(sparse_vector.keys()), # Sparse token IDs (e.g. BM25 terms)
values=list(sparse_vector.values()) # Corresponding weights
),
using="sparse", # Use the sparse vector field
limit=limit,
query_filter=models.Filter(
must=[models.FieldCondition(
key="site_id",
match=models.MatchValue(value=site_id)
)]
)
)
],
# Apply Reciprocal Rank Fusion (RRF) to merge dense + sparse results
query=models.RrfQuery(rrf=models.Rrf(k=60)),
# Final result limit after fusion
limit=limit,
# Fetch only the fields we care about in the result
with_payload=models.WithPayloadSelector(
include=models.PayloadIncludeSelector(fields=["post_id", "text"])
),
)
# Extract simplified result objects
return [
{
"id": point.payload.get("post_id"),
"text": point.payload.get("text"),
"score": point.score
}
for point in response
if point.payload is not None
]
(Note: If you are doing rapid client-side experimentation or complex A/B testing with custom business weights, you can calculate fusion manually in your application code. But for predictable, low-latency production execution, offloading RRF entirely to the database layer is an absolute game-changer.)
The Vanilla Kubernetes Blueprint
To keep operations lean, I bypass Helm charts and operators entirely. Because Qdrant doesn’t require an external cluster state manager, you can coordinate a resilient, self-bootstrapping 3-node cluster natively inside a vanilla Kubernetes StatefulSet.
Here is the exact configuration shape I use to ensure peers bootstrap automatically using the stateful pod network identity:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: qdrant
spec:
replicas: 1 # Single-node for now; can be scaled out later with cluster mode
serviceName: qdrant # Required for stable DNS identity in StatefulSets
selector:
matchLabels:
app.kubernetes.io/name: qdrant
template:
metadata:
labels:
app.kubernetes.io/name: qdrant
spec:
initContainers:
# Ensure volumes have correct ownership before main container starts
- name: ensure-dir-ownership
image: docker.io/qdrant/qdrant:v1.13.4
command: ["chown", "-R", "1000:2000", "/qdrant/storage", "/qdrant/snapshots", "/qdrant/snapshot-restoration"]
volumeMounts:
- name: qdrant-storage
mountPath: /qdrant/storage
- name: qdrant-snapshots
mountPath: /qdrant/snapshots
- name: qdrant-snapshot-restoration
mountPath: /qdrant/snapshot-restoration
containers:
- name: qdrant
image: docker.io/qdrant/qdrant:v1.13.4
command: ["/bin/bash", "-c"]
args: ["./config/initialize.sh"] # Custom script for first-time init or snapshot restoration
env:
- name: QDRANT_INIT_FILE_PATH
value: /qdrant/init/.qdrant-initialized # Used by your script to detect first-time boot
ports:
- name: http
containerPort: 6333
- name: grpc
containerPort: 6334
readinessProbe:
httpGet:
path: /readyz
port: 6333 # Qdrant’s built-in readiness endpoint
securityContext:
runAsUser: 1000
runAsGroup: 2000
runAsNonRoot: true
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true # Enforces tight security profile
volumeMounts:
- name: qdrant-storage
mountPath: /qdrant/storage # Persistent vector index data
- name: qdrant-snapshots
mountPath: /qdrant/snapshots # Snapshot output directory
- name: qdrant-snapshot-restoration
mountPath: /qdrant/snapshot-restoration # Where snapshots get restored from
- name: qdrant-config
mountPath: /qdrant/config/initialize.sh
subPath: initialize.sh # Your bootstrap script
- name: qdrant-config
mountPath: /qdrant/config/production.yaml
subPath: production.yaml # Optional override config
- name: qdrant-init
mountPath: /qdrant/init # Temp marker dir for init checks
volumes:
- name: qdrant-config
configMap:
name: qdrant-config # Provides both the init script and config file
- name: qdrant-init
emptyDir: {} # Used for writing a boot-complete marker file
volumeClaimTemplates:
- metadata:
name: qdrant-storage
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 200Gi
- metadata:
name: qdrant-snapshots
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 200Gi
- metadata:
name: qdrant-snapshot-restoration
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 200Gi
Cluster mode in Qdrant doesn’t require an external consensus service. Instead, I use a tiny initialize.sh script that uses StatefulSet DNS and a consistent peer URI strategy. Pod 0 becomes the initial node, and all others bootstrap from it using –bootstrap.
#!/bin/sh
# Extract the pod index from the StatefulSet hostname
# e.g. qdrant-0 → 0, qdrant-2 → 2
SET_INDEX=$${HOSTNAME##*-}
# For the first pod (index 0), start the cluster and
# become the initial peer
# https://github.com/qdrant/qdrant/blob/master/tools/entrypoint.sh
if [ "$SET_INDEX" = "0" ]; then
exec ./entrypoint.sh --uri 'http://qdrant-0.qdrant:6335'
else
# For other pods, join the cluster by bootstrapping from pod 0
exec ./entrypoint.sh \
--bootstrap 'http://qdrant-0.qdrant:6335' \
--uri "http://qdrant-$SET_INDEX.qdrant:6335"
fi
Moving Forward Natively
If you are currently evaluating vector search engines for a multi-tenant or multi-site workload, save yourself the abstract benchmark review sessions and follow a boring, systematic migration path:
- Build a workload-accurate benchmark: Do not test using random Wikipedia datasets. Use your production product catalog, your exact sparse tokenizer, your real filters, and your real multi-tenant query distributions.
- Pre-index your payloads: Map out fields like
site_id,category, andbrandinto payload indexes before you push data to avoid paying an unindexed disk-access tax later. - Optimize for the bulk load: When performing backfills, temporarily adjust your configuration to drop
indexing_thresholdorm: 0to bypass HNSW graph construction overhead during initial hydration. Re-enable it only when your initial data is warm. - Automate your disaster recovery drills: Rebuild tolerance sounds great in architectural planning sessions, but it’s an entirely different story when an outage hits on a Friday evening. Leverage external, S3-compatible snapshotting from day one.
In the next post in this series, I’ll show you a bird’s-eye view of the overall infrastructure architecture. I’ll break down the main architectural components, map out what lives where, and look at how I’m running this cluster on bare-metal virtual servers inside Hetzner. Spoiler alert: because I appreciate highly performant, remarkably affordable, European-based cloud providers when I’m bootstrapping on my own dime.
If you want to track how to take hybrid search out of the research lab and make it stay completely boring in production, hit the follow button and stay tuned. For now, Qdrant does exactly what I ask of it: stay fast, stay boring, and stay out of the way.
find me:
in my mind:
- #artist 2
- #arts 4
- #away 3
- #bucharest 1
- #buggy 6
- #business 1
- #clothes 1
- #comics 1
- #contest 3
- #dragosvoicu 1
- #education 1
- #food 2
- #free-ideas 1
- #friends 14
- #hobby 23
- #howto 9
- #ideas 33
- #life lessons 4
- #me 59
- #medium 4
- #mobile fun 4
- #music 51
- #muvis 17
- #muviz 13
- #myth buxter 1
- #nice2know 15
- #night out 1
- #openmind 2
- #outside 3
- #poems 4
- #quotes 1
- #raspberry 4
- #remote 56
- #replied 51
- #sci-tech 7
- #sciencenews 1
- #sexaid 7
- #subway 39
- #th!nk 5
- #theater 1
- #zen! 4